
LLaVA
It means Large Language and Vision Assistant, basically we are talking about an LMM (Large Multimodal Model) which connects a vision encoder with an LLM for visual and language understanding.
Easy, isn’t it?
The floor is LLaVA (haha)
I mean, no, it’s not funny. It’s more like a 5th-grade children joke.
Joking, I love it ![]()
However, the work of the authors here is quite extensive and challenging:
- use a language-only model (GPT-4) to generate multimodal language-image instruction-following data for visual instruction tuning 1
- a large multimodal model (LMM)
- a multimodal instruction-tuning benchmark
This post will focus on the model architecture itself rather than to the other two key contributions.
Architecture
Keep in mind that we want an end-to-end trained language-vision multimodal model for multiple tasks.
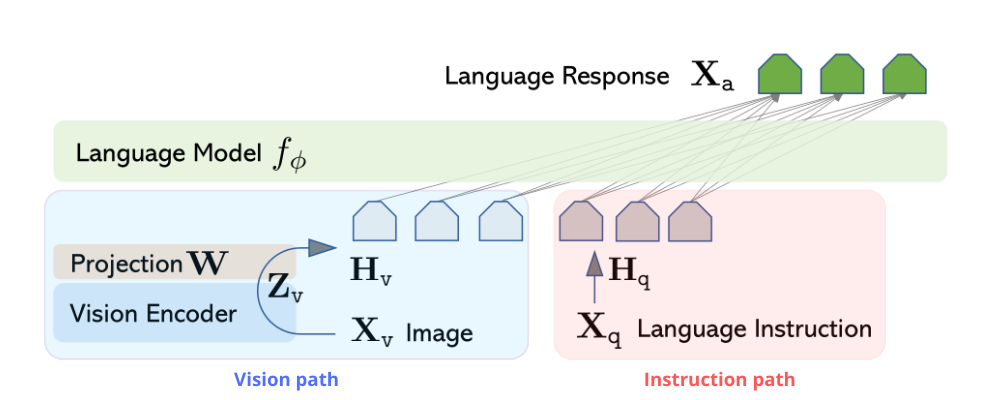 LLaVA architecture with its vision and instruction paths.
LLaVA architecture with its vision and instruction paths.
The vision path
The vision encoder $g(\cdot)$ converts the input image $\mathbf X_v$ into its latent representation $\mathbf Z_v$; then using the projection matrix $W$ we obtain the language embedding tokens $\mathbf H_v$, which have the same dimensionality as the word embedding space
\[\mathbf H_v = \mathbf W\cdot \mathbf Z_v=\mathbf W \cdot \mathbf g\left(\mathbf X_v\right)\]we ends up with $\mathbf H_v$ which is a sequence of visual tokens.
NOTE: sinc $W$ is lightweight, we can leverage this schema among data-intensive experiments.
The instruction path
$\mathbf X_q$ is the language instruction, which is the text (query or prompt) fed into the model, while $\mathbf H_q$ is its latent representation 2, i.e. the instruction embedding which is a sequence of textual tokens.
The training stage
Now that we have both the image and the query embeddings, we can concatenate them and treat them as a single vector $\mathbf H_v \odot \mathbf H_q$ which can be input to an LLM, so to obtain an answer $\mathbf X_a$.
This is what is done.
For each image $\mathbf X_v$ the aithors generates a multi-turn conversation
\[\left(\mathbf X_q^1, \mathbf X_a^1, \dots, \mathbf X_q^T, \mathbf X_a^T\right)\]where $T$ is the number of turns.
They treat the sequence of answers $\left(\mathbf X_a^1, \dots, \mathbf X_a^T\right)$ as the assistant replies to the instructions
leading to a unified format for the multimodal instruction-following sequence.
Then, the model is trained to predict the assistant answers $\mathbf X_a^i$ and to determine where to stop.
The paradigm shift
Until then (i.e. 12/2024), the instruction-following paradigm in computer vision were mainly two approaches:
- train an end-to-end model for a specific research topic (i.e. vision-language navigation)
- coordinates various models using a system
these models do not generalize beyond their target tasks, they are highly domain-specific. LLaVA, in contrast, wants to be a unified multimodal model which follows and understands instructions along a wide variety of visual tasks, using both natural language and visual images as input.
In other words, we are trying to achieve good performance in the visual instruction following field, which tests the capabilities of a multimodal model to understand and respond accurately to natural language instructions that relate to visual content.
In this way, the very same model can handle (for example):
- a dialogue
- question answering
- image understanding
- vision-language tasks
without being re-trained or specialized for each of these tasks.
Other contributions
Moreover, the authors of the paper produced two evaluation benchmarks for the visual instruction following task, with challenging application-oriented tasks, one on the COCO dataset while the other In-the-wild.
Conclusions
This is a paper of 2023/2024, so is has its limitations and is being surpassed ,but is still a good baseline.
I wanted to bring it for its importance in the VLMs and Foundation Models fields. I’m really interested to them, and you should expect some further posts in these directions.
I hope you enjoyed it!
See you in the next post ![]()