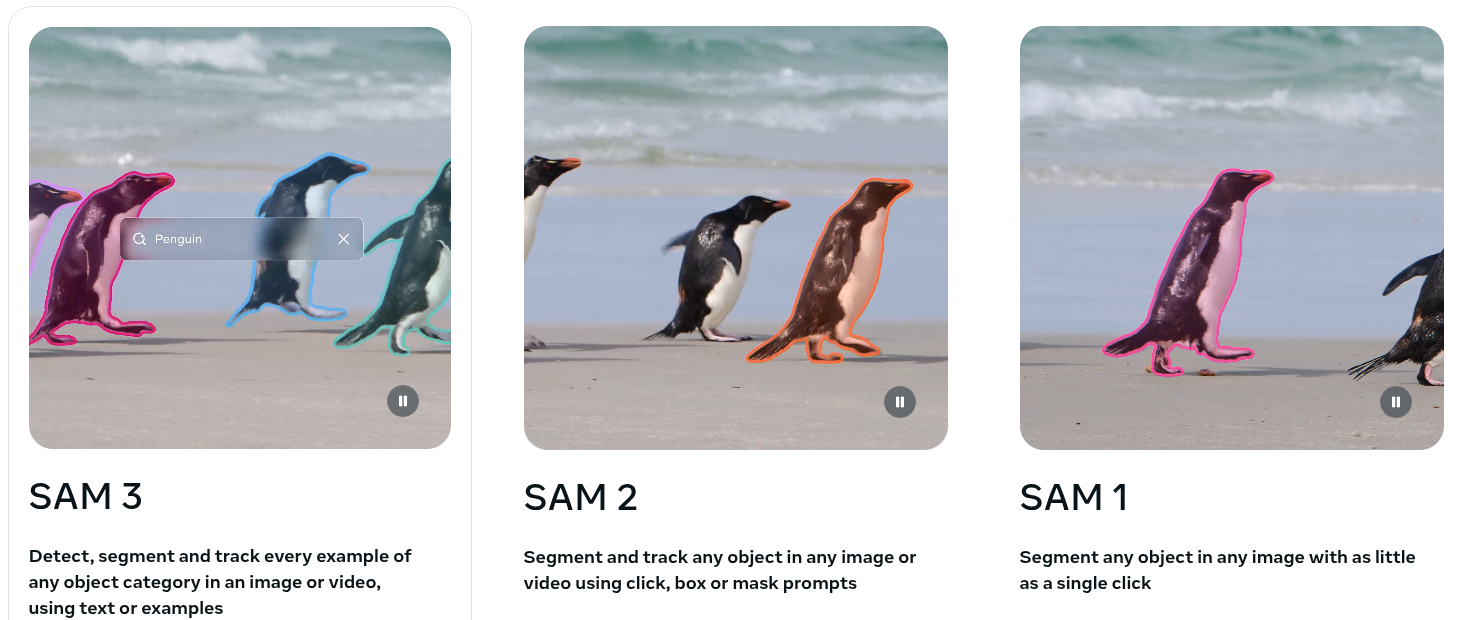
SAM 3
Just one word (actually two) OPEN SOURCE.
Meta Superintelligence Labs which is a Meta’s division launched just 6 months ago, dropped one of the biggest achievements in the Image/Video Segmentation landscape.
Let’s dive in the advancements that SAM-3 (the model we are referring to) brings to the field, by demystifying the paper, and making it more accessible to a broader basin of people.
Background
Classic Object-Detection
Before the “set prediction” era of DETR and SAM, we relied on dense prediction (think YOLO or Faster R-CNN). The philosophy was effectively: “Throw enough boxes at the wall and see what sticks.”
The core mechanism relies on a fixed grid. For every single cell in that grid, the model proposes multiple potential “Anchor Boxes” of different aspect ratios, asking: “Is there an object center here?”
The Size Problem
This approach creates a massive imbalance between the model’s output size and the actual number of objects.
Here’s an example. Imagine an input image containing just 2 cats.
To find them, a classic detector doesn’t just guess twice. It processes a feature grid (say, $30 \times 30$) and proposes multiple boxes for every cell (say 2). Considering a closed-vocabulary problem with 10 classes
\[30 \times 30 \times (2*5+10) = 8,000 \text{ predictions}\]So, for 2 real objects, the classic detector outputs 8,000 bounding boxes.
Most of these are garbage (background) or near-duplicates (slightly shifted versions of the same cat). This forces us to use heavy post-processing (Non-Maximum Suppression) to clean up the mess.
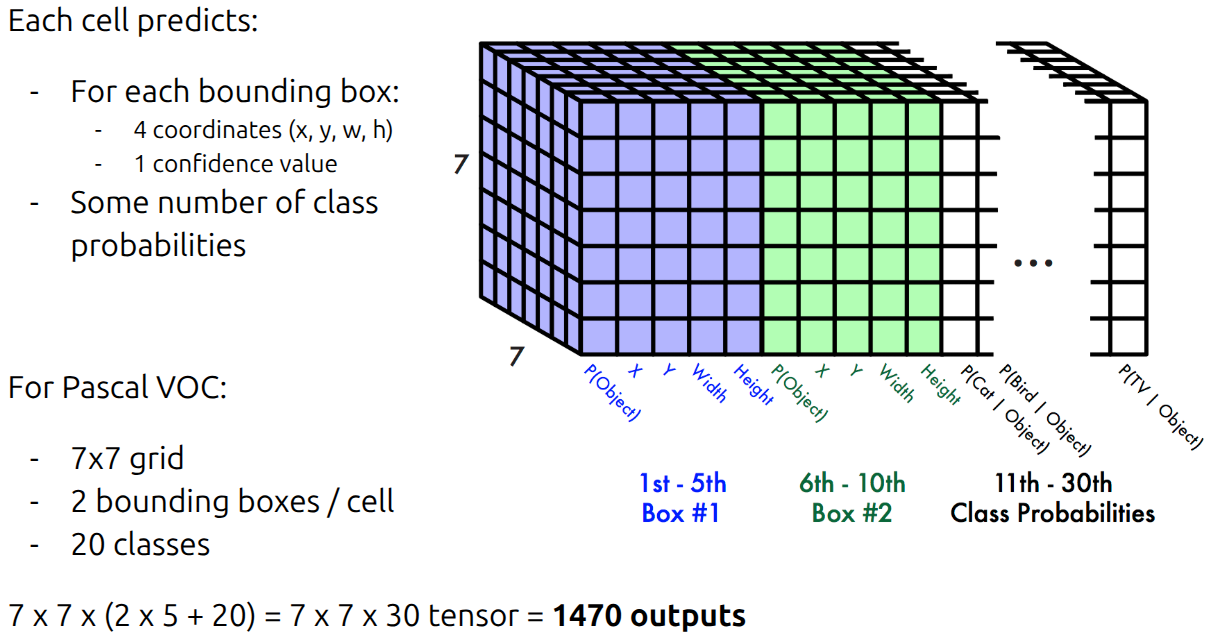 slide from YOLO CVPR 2016 presentation.
slide from YOLO CVPR 2016 presentation.
The Hungarian algorithm
Back in 2022 my Operative Research’s professor showed to the class this problem using the “Candidates and Jobs” example, and states the following:
- we have 6 candidates that apply to zero or more jobs
- we have 6 job openings that accept zero or more candidates
we must try to satisfy each of these 6+6 entities ensuring that each candidate gets hired by one company (represented by a job position) and each company hires just one candidate.
Since some candidates may not apply to any job position, while some others may apply to multiple positions, some job positions can receive either multiple, one, or no candidates.
This problem is called also “Assignment problem”, and has been successfully solved using the Hungarian algorithm in polynomial time.
We’ll use this in DETR.
DETR
Back in 2020, DETR has been an high magnitude paper 1. It successfully shifted the way object detection has been done since then. Without delving too much in the details, for the recipe you need to know:
1) bipartite graph matching (also, assignment problem) 2) hungarian algorithm
Now, DETR handles the Object Detection task as a set prediction, meaning that the network does not anymore output a big ordered tensor of prediction (like YOLO), but a fixed set of (unordered) predictions. Having a set of predictions, we can match them with the ground truth labels +1 (the “no-object” class).
This seems an assignment problem. Well, actually, it is, and we know how to deal with it.
DETR vs Classic approach
Let’s answer “Why does DETR is so important?”
1) The many-to-one VS one-to-one
Classic YOLO-like approach to object detection leverage heavily prediction post-processing to suppress (using NMS) the overlapping bounding boxes, keeping the “best” one. This approach is called “many-to-one”, the architecture internally leverage the prediction of multiple similar bounding-boxes around the very same object to later obtain the best one.
Is this a “waste” of computation? It can be improved; and this is exactly what DETR does.
DETR uses a one-to-one approach, the network outputs a set on prediction which must be matched (using hungarian algorithm) to the ground truth. Moreover, the loss is weights the number of predictions, leading the network to avoid outputting too many bounding-boxes for the very same object. It encourage the production of a single, useful prediction.
2) The Local rule (IoU) VS global rule (bipartite matching)
Classic object detection approach is local, i.e. it uses IoU to select whether a prediction matches or not.
DETR uses bipartite graph matching, so it doesn’t check for “Does this specific index match?” it seek for the best unique assignment for the entire set: looks at the $N$ predictions and the $M$ ground-truth and says: “If prediction A takes ground truth 1, then prediction B cannot take ground truth 1, even if it overlaps”.
SAM 3
Now we get to the chunky part.
The first sentence of the paper about the model is the following
SAM 3 is a generalization of SAM 2, supporting the new PCS task as well as the PVS task.
Do you need knowledge about SAM 2 to learn SAM 3? No, but follow me, it will be easier.
Promptable Concept Segmentation (PCS)
This is the “give me a simple prompt, I’ll segment all the related instances in the image”, if we are referring to videos ($\le 30$ secs), the model is able also to track instances across frames.
The word “simple” is quite needed; here the authors wants to segment and track every single instance of a concept in an image/video, and so the prompt “person”, or “yellow bird” rather than “the man in the red shirt standing next to the car” just fits better.
However as we approach the “less context” world, some problems arises. With enough context, a model could be able to discern:
- polysemy (“mouse” device vs. animal)
- subjective descriptors (“cozy”, “large”)
- vague phrases (“brand identity”)
- boundary ambiguity (should the word “mirror” includes the surrounding frame?)
While some others approaches carefully cure the concepts vocabulary, setting a clear definition of al classes of interest, others simply uses closed-vocabulary corpora, which slightly alleviates such problem.
However, here the authors wants to address the open-vocabulary concept detection challenge. The ambiguity gets addressed by:
- adapting the evaluation protocol to allow multiple interpretations
- designing the data pipeline to minimize ambiguity
- an ambiguity module, which is a MoE (K=2) head supervising only the lowest-loss expert, and a classification head which selects the expert with the highest probability of being correct.
 Two interpretations of the noun phrase “large circular shape” learned by two Experts
Two interpretations of the noun phrase “large circular shape” learned by two Experts
A last important thing is that the concept prompts are global to all frames, but can be progressively refined on individual frames using positive/negative bounding boxes.
 Illustration of supported initial and optional interactive refinement prompts in the PCS task.
Illustration of supported initial and optional interactive refinement prompts in the PCS task.
Promptable Visual Segmentation (PVS)
The idea is the very same of PCS, it uses visual prompt (in contrast of concept prompts for PCS) which define the objects to be (individually) segmented spatio-temporally. Visual prompts can be: points, boxes or masks.
As for the PCS, we can iteratively add visual prompts to refine the target masks, both by adding or removing objects using masks.
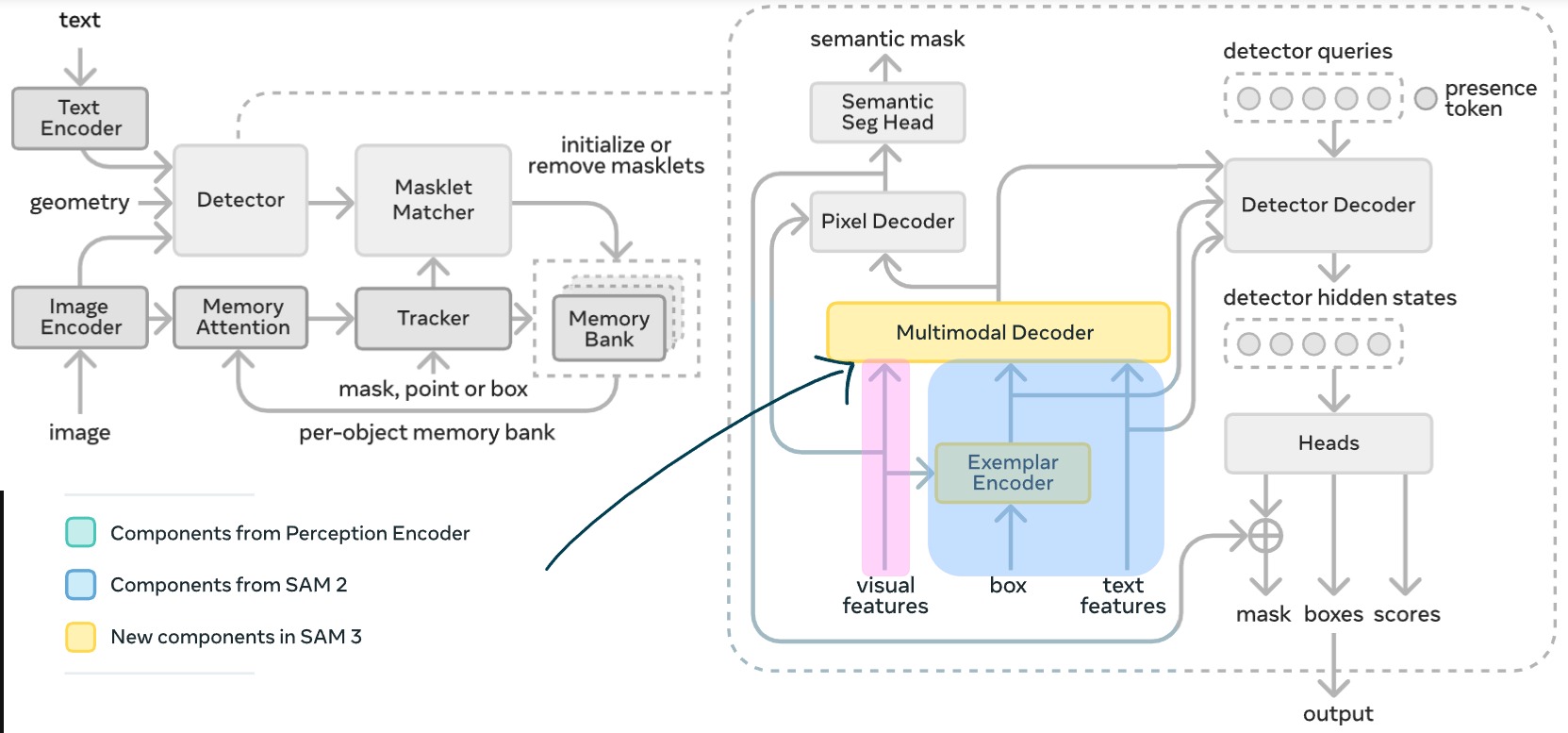
Architecture
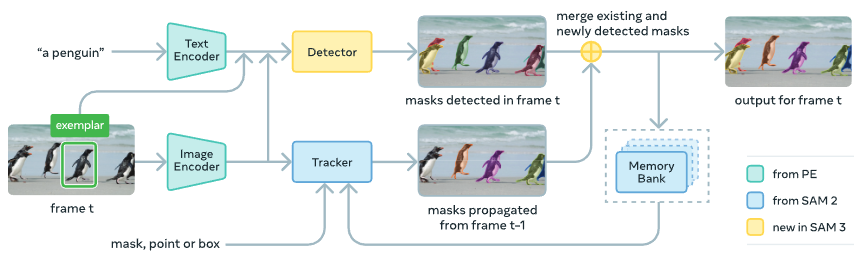 SAM 3 architecture overview.
SAM 3 architecture overview.
Citing from the original paper
Our architecture is broadly based on the SAM and (M)DETR
where the “M” stands for modulated2, which in addition to the classic DETR, it has a text encoder (RoBERTa), which allows the model to perform object classification (in DETR-style) conditioned by a descriptive textual prompt.
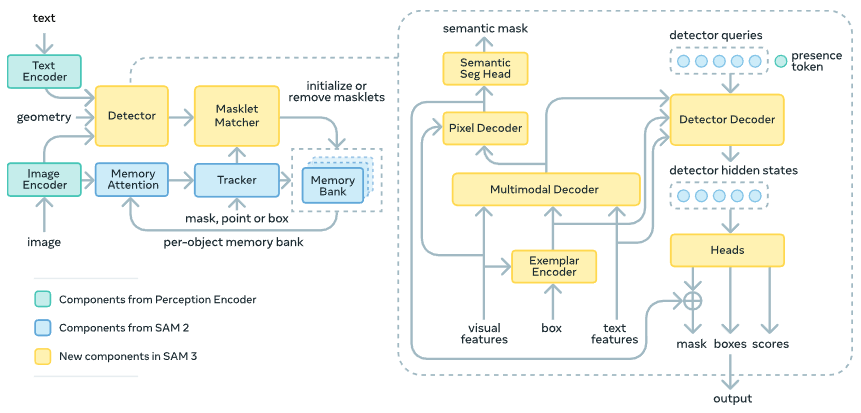 SAM 3 architecture detailed.
SAM 3 architecture detailed.
So, we have an image (or a video frame), and/or we have a text prompt (the “Concept”). How do they talk to each other to produce a mask?
Here is the recipe:
The Perception Encoder
In SAM 2 the authors used Hiera3 vision encoder, which is a hierarchical model optimized for visual feature extraction suitable for prompt-based segmentation. Even if it has a strong localization capability and efficiency, the authors shifted to a unified vision-language backbone that jointly process images and text from the start, the Perception Encoder4 (PE).
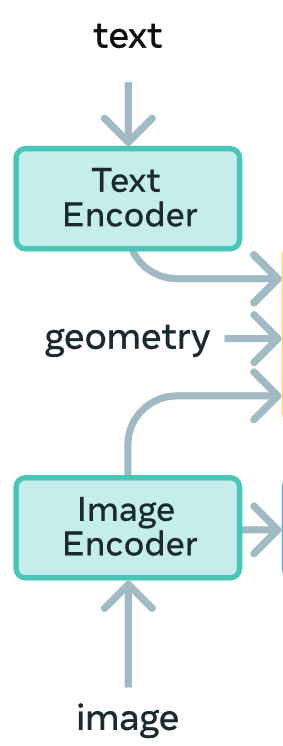 SAM 3's Perception Encoder.
SAM 3's Perception Encoder.
The reason, citing the authors, is because the single PVS task, at the core of SAM 2, is “geometric”, i.e. matches low-level features, and isn’t enough for their purposes. And so instead of relying just on geometric features, SAM 3 needs also semantics. Achieved with the introduction of PE to tackle the PCS task.
Zooming in the anatomy, PE is formed by a text encoder and an image encoder; they are transformers trained using constrastive vision language training.
Mixing all together, allows the model to better understand concepts (semantic meaning) rather than “just” features (i.e. geometry, edges and texture), and this is the fundamental shift from SAM 2 to SAM 3; or in other words, from Hiera to PE.
The Presence Head
In standard object detection (DETR/YOLO), model suffer from a “hallucination” problem, they often seems obliged to find something in images, even when it is not there.
This is also called “forced detection” or “identity crisis”, and behave as follows: standard object detection models works with Object Queries, i.e. a fixed number of “empty slots” that the model send into the given image to find things. Shortly “I have 100 slots, I must fill them with the best matches I can find, or label them as background”.
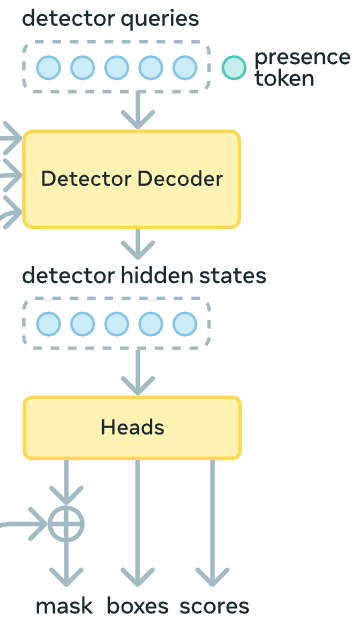 SAM 3's Presence Token flow. Initially gets processed by a Detector Decoder,; then, its output, will be fed into the heads block, which will convert it to a probability score.
SAM 3's Presence Token flow. Initially gets processed by a Detector Decoder,; then, its output, will be fed into the heads block, which will convert it to a probability score.
When you prompt a concept like “Unicorn”, on an image of an empty street, standard models often try to force those 100 Object QUeries to look for “Unicorn-like” features. Also if there are no unicorns in an empty street, a fire hydrant or a shadow might have a tiny bit of “vertical shape” or “dark silhouette” which resemble a unicorn feature, and may give to the hydrant a 15% of confidence score for “Unicorn”.
In short: standard object detection algorithms struggle to say “No, that concept is not here”.
The presence head fix this. Introducing it the authors decouple Recognition from Localization, i.e. “Is it there?” from “Where is it?”; since this token is solely responsible for predicting whether the target concept in the form of a noun phrase (NP) is present in the image/frame.
How? Instead of asking 100 object queries to look for the concept, a global Presence Token is employed. It will attend the entire image context from the PE, and gets trained to answer a simple question: “Does the concept [X] exist in this image at all?”; the output is a probability score $P_\text{presence}\in[0, 1]$.
The localization problem
This “global score” is then used to gate the predictions, which in contrast are made locally using Object-Queries; in this way, each query must solve what the authors call “localization problem”
\[\text{Score}_\text{final}=P_\text{presence} \times P_\text{local\_object\_query}\]So that, if the Presence Head says there is a 0.01% chance of a “unicorn” being in the image, it crushes the confidence scores of all the local object queries to near zero.
The Fusion Encoder
This is where the (M)DETR influence kicks in. The authors calls text and geometry/exemplar tokens as prompt tokens.
The fusion encoder (in the image Multimodal Decoder) accept:
- (unconditioned) Visual features from the PE’s vision branch.
- Prompt Embeddings from PE’s text branch (like RoBERTa) and Exemplar Encoder (if available).
While the PE provides aligned features, the Fusion Encoder ensures the visual map is conditioned on the concept we are looking for (e.g., “red sports car”), acting as the bridge between the raw backbone (PE) and the detector.
 Fusion encoder, dark blue arrow. Unconditioned visual features, pink box. Prompt embedding, lightblue box.
Fusion encoder, dark blue arrow. Unconditioned visual features, pink box. Prompt embedding, lightblue box.
It leverage the transformer architecture to perform bi-directional cross-attention. This means:
- the image features “look at” the text features to know what to highlight, and
- the text features “look at” the image to refine their representation based on the visual context
The output is a set of prompt-conditioned image features (recall that prompt tokens = text tokens + exemplar tokens). Unlike standard DETR, which feeds raw image features into the decoder, SAM 3 feeds these “concept-aware” features, making the job of the subsequent Object Queries easier: they aren’t searching a generic image, they are searching an image where the “Unicorn” features have already been highlighted and the background suppressed.
Long story short, the fusion encoder perform the binding of the two modalities, text (+exemplar) and image, coming from PE.
The Memory Bank
SAM 3 is a generalization of SAM 2; this means that it inherit the video capabilities. This is reflected with the presence of a Memory Bank of past frames’ features and predictions, also called “masklets” (temporal mask segments).
As you can imagine, this is crucial. When the user prompts “The protagonist”, the model must remember that the guy is blue shirt in frame 1 is the same guy in frame 100. This module links the current frame’s PE output with the historical context. So, this concept-centric design requires the identity maintenance, and it performs that via
- Spatial Memory: high-resolution features
- Object Pointers: lightweight vectors representing the semantic identity of the tracked object
In this way, SAM 3 is able to tracking not just “an object,” but “that specific instance of the concept” across frames (and so, time).
Conclusion
The authors didn’t produces just “SAM 2 with text”. It is a fundamental shift from Object-Queries-Centric segmentation to Concept-Centric segmentation. Is like the difference between choosing within a restaurant menù, or asking to the chef to craft a dish following your description.
Now, go clone the repo and see if you can break it!